
Pentru a recapitula cele spuse până acum în primul și al doilea articol, este clar că atunci când construim un model, selecția elementelor de antrenament este cel mai dificil aspect. AutoML vă poate furniza o listă cu cele mai bune modele, datorită datelor metrice de evaluare care acompaniază fiecare model. Pregătirea datelor este complexă și necesită mult timp. Alături de fluxul de antrenament (training pipeline), datele pregătite construiesc un model pregătit să facă predicții.
După ce avem un model de machine learning putem să îl punem în aplicare și să prezicem niște date.
var sampleData = new ModelInput
{
Luminosity = lux,
Temperature = temp,
Infrared = infra,
CreatedAt = DateTime.Now.ToString("dd/MM/yyyy hh:mm:ss"),
Distance = 0
};
var predictor = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(model);
var predicted = predictor.Predict(sampleData);
Console.WriteLine(predicted.PredictedLabel);
Console.WriteLine(predicted.Score);Fie că tocmai am creat modelul, fie că l-am încărcat dintr-un fișier salvat anterior, tot ce avem de făcut este să instanțiem un obiect de tip motor de predicție (prediction engine) folosind CreatePredictionEngine și să apelăm metoda Predict. Vom obține PredictedLabel și un Score pentru aceasta.
Consumați modelul într-un scenariu Enterprise
Abordarea anterioară pentru realizarea predicțiilor funcționează bine pentru scenariile simple (precum aplicațiile consolă), dar ce se întâmplă când vrem să scalăm contextul într-un scenariu complex?
Obiectul PredictionEngine nu este thread-safe (nu funcționează corect când avem mai multe threaduri desfășurate în paralel, iar accesul la datele partajate trebuie serializat), pentru aplicații web unde s-ar putea să fie nevoie să creăm, iar apoi să distrugem obiectele de tip motoare de predicție. Pentru acest caz este nevoie de o abordare complexă.
La o primă vedere, pentru scenariile multi-thread, cum sunt aplicațiile web (folosind HTTP sau websockets), am putea crea o instanță unică (singleton) pentru obiectul PredictionEngine, dar motorul de predicție nu este thread-safe ca obiect, ceea ce poate afecta funcționalitatea. Așadar, avem nevoie de altceva.
Pachetul nuget Microsoft.Extensions.ML oferă un obiect numit PredictionEnginePool care dispune de un set de obiecte PredictionEngine inițializate, gata de a fi folosite.
Pentru inițializarea bazei de obiecte, trebuie să adăugăm AddPredictionEnginePool la servicii în fișierul Startup.cs.
public void ConfigureServices(IServiceCollection services)
{
services.AddPredictionEnginePool<ModelInput, ModelOutput>()
.FromFile(modelName: "Model", filePath:"Model.zip);
}Apoi poate fi consumat astfel:
public class PredictController : Controller
{
private readonly PredictionEnginePool<ModelInput, ModelOutput> _engine;
public PredictController(PredictionEnginePool<ModelInput, ModelOutput> engine)
{
_engine = engine;
}
[HttpPost]
public IActionResult Post(ModelInput input)
{
ModelOutput prediction = _engine.Predict(modelName: "Model", example: input);
return Ok(prediction);
}
}Modelele de machine learning pot fi reantrenate și relansate oricând, situație care poate genera downtime pentru aplicație. Nu vă îngrijorați, serviciul PredictionEnginePool oferă o modalitate de a reîncărca un model reantrenat fără a dezactiva aplicația.
Extensii pentru Deep Learning
“ML.NET este o platformă extensibilă. Prin urmare, puteți consuma celelalte paradigme ML populare (TensorFlow, ONNX, Infer.NET, și nu numai)”, este ceea ce citim din documentație, iar ML.NET devine astfel un factor important în universul Deep Learning. ML.NET nu este (încă) capabil să antreneze un model de deep learning de la zero.
Consumați modelele TensorFlow
TensorFlow este o paradigmă open source pentru deep learning și machine learning creată de Google în 2015. TensorFlow are suport pentru Python, Java, C++, C# și multe alte limbaje. Pentru C# puteți lucra cu TensorFlow.NET SDK dacă plănuiți să construiți, antrena și infera modele deep learning. TensorFlow.NET respectă îndeaproape convențiile de denumire Python și este open source. Desigur, este nevoie de ceva timp pentru a-l învăța și aveți nevoie de abilități data science. Ce se întâmplă dacă nu aveți nici timp, nici abilități?
Momentan, ML.NET (folosind pachetul nuget Microsoft.ML.TensorFlow) este limitat la scoring și transferul informației învățate (transfer learning). Avantajul este că puteți folosi, într-o manieră foarte simplă, modelele TensorFlow antrenate cu alte paradigme (Azure Custom Vision, Keras etc.) pentru studii de caz variate precum: computer vision, recunoașterea imaginilor, recunoașterea vocii, traduceri, recunoașterea scrisului de mână și nu numai. Totuși, antrenamentul unui model deep learning de la zero, precum Inception, poate lua câteva zile sau săptămâni (în funcție de puterea de calcul).
De exemplu, poți face scoring pe imagini folosind modelul TensorFlow Inception, un model static salvat în format protobuf (.pb). Acest model este utilizat pentru clasificarea de imagini și a fost preantrenat cu imagini fotografice ale diferitelor obiecte precum animale, legume și alte obiecte din viața cotidiană. Imaginile sunt clasificate în 1000 (o mie) de clase diferite, iar modelul va produce cele mai asemănătoare clase pentru imaginea voastră, cu scorul aferent.
În prima linie de cod, apelăm metoda LoadFromEnumerable cu o listă goală de obiecte. Deorece facem doar scoring, nu trebuie să încărcăm date de intrare când construim pipeline-ul de antrenament, dar avem nevoie de aceste lucruri când citim schema datelor. Mai apoi, se construiește un pipeline de antrenament cu o imagine și model loaders, dar și cu transformări precum redimensionarea imaginii și extragerea pixelilor, ultimele operațiuni fiind menite pentru obținerea scorului.
var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());
var pipeline = mlContext
.Transforms.LoadImages(
outputColumnName: "input",
imageFolder: imagesFolder,
inputColumnName: nameof(ImageNetData.ImagePath))
.Append(mlContext.Transforms.ResizeImages(
outputColumnName: "input",
imageWidth: ImageNetSettings.imageWidth,
imageHeight: ImageNetSettings.imageHeight,
inputColumnName: "input"))
.Append(mlContext.Transforms.ExtractPixels(
outputColumnName: "input",
interleavePixelColors: ImageNetSettings.channelsLast,
offsetImage: ImageNetSettings.mean))
.Append(mlContext.Model
.LoadTensorFlowModel(modelLocation)
.ScoreTensorFlowModel(
inputColumnNames: new[] { "input" },
outputColumnNames: new[] { "softmax2" },
addBatchDimensionInput: true));
ITransformer model = pipeline.Fit(data);
var predictor = mlContext.Model
.CreatePredictionEngine<ImageNetData, ImageNetPrediction>(model);
predictor.Predict(new ImageNetData { ImagePath = path, Label = label });De multe ori, nu vrem să limităm predicțiile la clasele existente. În loc de a face acest lucru, veți dori să interceptați voi înșivă nivelul final și să completați voi antrenamentul cu setul vostru de imagini pentru clasele dorite.
Identificarea nivelelor dintr-un grafic nu este magie neagră și cel mai probabil nu avem nevoie să cunoaștem modelul. Așadar, un instrument precum Netron este o metodă excelentă de vizualizare.
Să ne îndreptăm atenția spre nivelul softmax spre final. În mod normal, pentru clasificarea imaginilor utilizând miile de clase originale, dispunem de nivelul softmax care selectează rezultatul cel mai bun, deci clasificare finală (identificarea clasei) este realizată de modelul în sine.
Când dorim să completăm antrenamentul cu setul nostru de date (clase și imagini), ne referim la transfer learning (transferul informațiilor învățate).
Să ne uităm întâi la cod, iar apoi să intrăm în detalii.
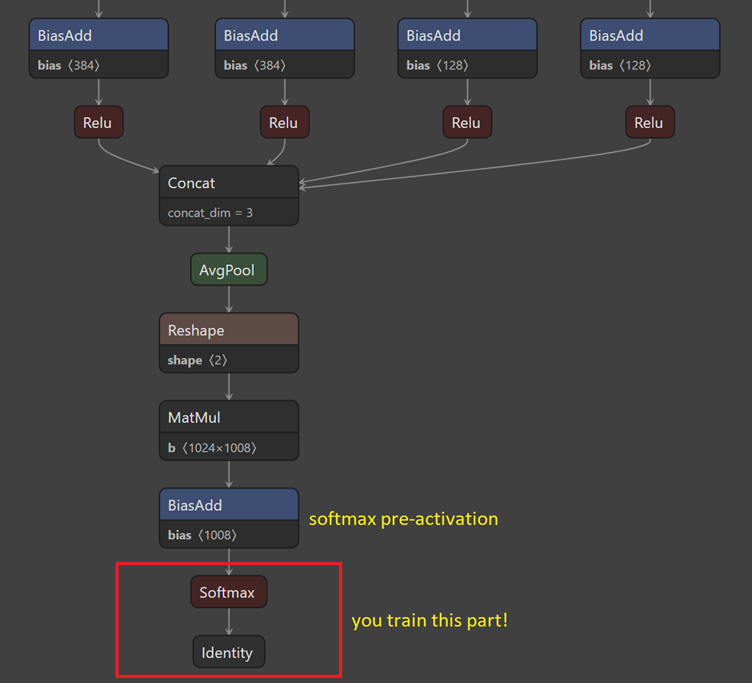
var data = mlContext.Data.LoadFromTextFile<ImageNetData>(dataLocation);
var pipeline = mlContext
.Transforms.Conversion.MapValueToKey(
outputColumnName: LabelToKey,
inputColumnName: nameof(ImageNetData.Label))
.Append(mlContext.Transforms.LoadImages(
outputColumnName: "input",
imageFolder: trainImagesFolder,
inputColumnName: nameof(ImageNetData.ImagePath)))
.Append(mlContext.Transforms.ResizeImages(
outputColumnName: "input",
imageWidth: ImageNetSettings.imageWidth,
imageHeight: ImageNetSettings.imageHeight,
inputColumnName: "input"))
.Append(mlContext.Transforms.ExtractPixels(
outputColumnName: "input",
interleavePixelColors: ImageNetSettings
.channelsLast,
offsetImage: ImageNetSettings.mean))
.Append(mlContext.Model
.LoadTensorFlowModel(modelLocation)
.ScoreTensorFlowModel(
inputColumnNames: new[] { "input" },
outputColumnNames: new[] { "softmax2_pre_activation" },
addBatchDimensionInput: true))
.Append(mlContext.MulticlassClassification
.Trainers.LbfgsMaximumEntropy(labelColumnName: LabelToKey, featureColumnName: "softmax2_pre_activation"))
.Append(mlContext.Transforms.Conversion
.MapKeyToValue(PredictedLabelValue, PredictedLabel))
.AppendCacheCheckpoint(mlContext);
ITransformer model = pipeline.Fit(data);
var predictor = mlContext.Model.CreatePredictionEngine<ImageNetData, ImageNetPrediction>(model);
predictor.Predict(new ImageNetData { ImagePath = path, Label = label });Comparând codul pentru transfer learning cu cel de scoring, observăm că:
- metoda LoadFromTextFile primește locația datelor ca argument, iar locația conține imagini și un fișier .csv ce conține clasele;
- componenta pipeline se oprește la nivelul softmax2_pre_activation iar restul nivelelor, precum softmax2, sunt ignorate;
- trebuie să avem grijă de multi-clasificare, deoarece avem propriile noastre clase (nu cele 1000 de clase originale).
Consumați modelele ONNX
ONNX este un format standard, interoperabil și deschis creat de Facebook și Microsoft pentru modelele de deep learning. Cu ONNX, programatorii AI pot muta mai ușor modelele de la un instrument (tool) la altul. Precum TensorFlow, multe studii de caz sunt acoperite de modelele ONNX existente: clasificarea imaginilor, detecția obiectelor și segmentarea imaginii, analiza feței și a gesturilor, manipularea imaginii, procesarea vorbirii și cea audio, traducerea automată, modelarea limbajului și alte modele interesante.
YOLO (You Only Look Once) este un model bine cunoscut de deep learning pentru detecția obiectelor multiple în timp real (\~30 fps pe CPU), model capabil să identifice obiectele din 80 de clase. Sunt versiuni mai mari precum YOLO9000 care extinde YOLO pentru a clasifica obiectele în mai mult de 9000 de clase. O versiune mai mică antrenată cu 20 de clase obiect numite Tiny YOLO este ceea ce vom folosi în mostra noastră de cod. Clasele existente sunt:
- person (persoană)
- bird (pasăre), cat (pisică), cow (vacă), dog (câine), horse (cal), sheep (oaie)
- airplane (avion), bicycle (bicicletă), boat (barcă), bus (autobus), car (mașină), motorbike (motocicletă), train (tren)
- bottle (sticlă), chair (scaun), dining table (masă de servit mâncare), potted plant (plantă în vază), sofa (canapea), tv/monitor (TV)
Din perspectiva codului, trebuie să încărcăm datele cu o listă goală (așa cum am făcut pentru TensorFlow scoring) pentru a citi schema datelor, dar restul este foarte similar cu scoringul de la TensorFlow. Pentru a interpreta rezultatele se folosește o logică mai consistentă. Aceasta este din cauza datelor de ieșire. Modelul returnează o listă a celor mai bine prezise obiecte alături de gradul lor de precizie și de un bounding box.

var data = mlContext.Data.LoadFromEnumerable(
new List<ImageNetData>());
var pipeline = mlContext.Transforms.LoadImages(
outputColumnName: "image",
imageFolder: "",
inputColumnName: nameof(ImageNetData.ImagePath))
.Append(mlContext.Transforms.ResizeImages(outputColumnName: "image",
imageWidth: ImageNetSettings.imageWidth,
imageHeight: ImageNetSettings.imageHeight,
inputColumnName: "image"))
.Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image"))
.Append(mlContext.Transforms.ApplyOnnxModel(
modelFile: modelLocation,
outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput },
inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));
var model = pipeline.Fit(data);Microsoft ML.NET se îmbunătățește în permanență cu noi funcționalități, antrenori (trainers) și scenarii de antrenament. De exemplu, suportul GPU pentru CUDA a fost adăugat recent pentru [re]antrenarea locală a modelelor noastre și suportul inferențelor pentru aplicații Blazor client-side (folosind WebAssembly).
De ce iubesc ML.NET?
ML.NET nu va înlocui framework-uri precum TensorFlow, dar luând în calcul că AI va fi adoptată de majoritatea aplicațiilor, în calitate de programator .NET fără cunoștințe solide de știință, prefer o paradigmă code-first.
ML.NET este foarte ușor de învățat și îl puteți folosi pe diferite platforme precum Linux, macOS sau Windows cu C# sau F#.
Mă puteți găsi pe github.com/dcostea și twitter.com/dfcostea pentru mai multe informații și proiecte interesante.
2 thoughts on “[Romanian] Machine Learning 101 cu Microsoft ML.NET (partea 3/3)”
Comments are closed.