
La finalul primei părți din seria curentă de articole, am ajuns la o linie de preprocesare, pregătită să încarce date și să concateneze elementele selectate pentru antrenarea modelului într-un feature special numit Features și un feature țintă numit Label care deservește o categorie unde elementele selectate sunt supuse clasificării. Dacă nu avem coloana Label în setul nostru de date, trebuie să adnotăm câmpul țintă astfel. Evident, pentru alte scenarii s-ar putea ca altul să fie feature-ul țintă pe care trebuie să îl adnotăm:
[ColumnName("Label")]
public string Source { get; set; }Contextul ML
Înainte de a construi linia de procesare (pipeline), doresc să explic ce este containerul de cataloage MLContext. În acest catalog găsim componente cum sunt trainer, încărcător de date, transformator de date și predictori, pe care le putem folosi pentru o varietate de acțiuni: regresie, clasificare, detecția anomaliilor, recomandări, clustering (grupare), predicții, clasificarea imaginilor și detectarea obiectelor. Multe dintre ele vin cu pachetele nuget adiționale.
Parametrul seed este folosit intern de separatori (splitters) și de unii trainers pentru a da modelului de antrenament un comportament deterministic, lucru foarte util pentru unit teste.
Ce este ML trainer?
Există mai mulți algoritmi de antrenament pentru fiecare sarcină ML.NET disponibilă. Aceștia iau forma de trainers ce pot fi găsiți în cataloagele corespondente. De exemplu, Stochastic Dual Coordinated Ascent pe care l-am folosit în acest articol este disponibil sub formă de Sdca (pentru regresie), SdcaNonCalibrated și SdcaLogisticRegression (pentru clasificare binară), și SdcaNonCalibrated și SdcaMaximumEntropy (pentru clasificare multiplă).
Să revenim la linia de preprocesare creată în partea întâi a acestei serii de articole:
var featureColumns = new string[] {
"Temperature",
"Luminosity",
"Infrared",
"Distance" };
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.Concatenate("Features", featureColumns));Putem continua cu extinderea linie de procesare selectând un trainer.
var trainingPipeline = preprocessingPipeline
.Append(mlContext.MulticlassClassification.Trainers.SdcaNonCalibrated("Label", "Features"));Nu putem considera că am terminat până când nu am ajuns la etapa de postprocesare care, în cazul nostru, este maparea cheie-valoare pentru a face predicția interpretabilă (vedeți mai sus maparea cheie-valoare din linia de preprocesare).
var postprocessingPipeline = trainingPipeline.Append(mlContext.Transforms.Conversion.MapKeyToValue ("PredictedLabel"));Este linia de procesare și antrenament suficientă pentru a crea un model? Evident că nu. Mai avem nevoie de date pentru ca modelul să fie antrenat, însă până când nu apelăm metoda Fit în linia de procesare, nu primim niciun tip de date de la loader, cu excepția schemei sale, iar acest lucru se întâmpla pentru că DataView încarcă datele întârziat, în ultimul moment, similar cu Linq IEnumerable.
var model = postprocessingPipeline.Fit(trainingData);Ponderi și erori (Weights și biases)
În esență, un trainer este un algoritm generic ce poate să își ajusteze valorile ponderate și erorile prin antrenamentul datelor. Cu cât avem mai multe date, cu atât e mai bună modelarea.
VBuffer <float>[] weights = default;
model.Model.GetWeights(ref weights, out int numClasses);
var biases = model.Model.GetBiases();Modelați componentele Builder și Automated ML
Probabil că prima grijă a unui programator, când vorbim de machine learning, este alegerea unui trainer bun, dar această sarcină nu trebuie să fie exclusiv apanajul omului de știință. ML.NET conține o tehnologie excelentă numită Automated ML (AutoML), care are mai multe variante:
- ML.NET Model Builder (un tool vizual Machine Learning din Visual Studio 2017+) pentru a experimenta cu diferite sarcini machine learning pe seturi de date și pentru a genera cod C# gata de utilizat;
- ML.NET CLI (putem instala acest tool la nivel global) care, odată instalat, ne permite să alegem o sarcină de lucru de machine learning și un set de date pentru a genera modelul ML.NET, dar și cod C# gata de utilizat (similar cu Model Builder).
mlnet regression --dataset "sensors_data.csv" --train-time 600- C#/F# – cod pe care îl putem integra în aplicațiile noastre
var experimentResult = Context.Auto()
.CreateMulticlassClassificationExperiment(ExperimentTime)
.Execute(trainingDataView);
var bestRun = experimentResult.BestRun;
var model = bestRun.Model;Măsurați calitatea modelului
Validați modelul
Am mai făcut referire la modelul de performanță, dar cum îl putem măsura?
O tehnică cunoscută de validare este validarea încrucișată k-fold care poate fi folosită pentru ajustarea hiperparametrilor. Un hiperparametru este un parametru utilizat pentru a controla procesul de învățare și pentru a modifica semnătura metodei unui trainer. Parametrii model sunt elemente interne modelelor, acestea putând fi învățate direct din datele de antrenament, hiperparametrii neputând face acest lucru.
var crossValidationResults = mlContext.MulticlassClassification.CrossValidate(trainingData,
postprocessingPipeline, numberOfFolds: 5, labelColumnName: "Label");Validarea încrucișată verifică consistența modelului fiind responsabilă de:
- Împărțirea setului de date în sub-seturile de date k (folds sau eșantioane);
- Antrenarea modelului pe k – 1 eșantioane și lăsarea unui eșantion pentru testare;
- Evaluarea modelului pe eșantionul de test;
- Repetarea pașilor precedenți pentru alt set de k – 1 folds astfel încât eșantionul de testare este diferit de eșantioanele de testare utilizate anterior;
- Calcularea datelor metrice medii, a deviației standard, a gradului de încredere.
Iată o reprezentare grafică pentru validarea încrucișată pe cinci eșantioane.
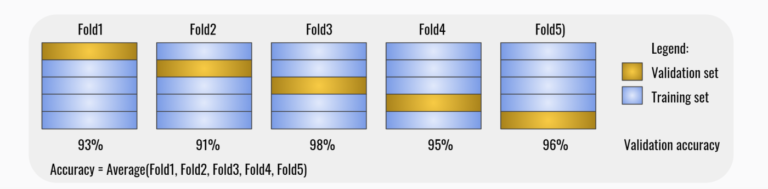
Observați că validarea încrucișată necesită mult timp, deoarece antrenează modelul de k ori. Nu ar trebuie să ne preocupe prea mult, deoarece acest lucru nu se întâmplă în producție. Este important de reținut că validarea încrucișată este o alegere bună când avem date limitate, deoarece aceasta reutilizează datele din setul de date de antrenament.
Așa cum se observă în tabelul de mai sus, acuratețea la nivel macro și micro este undeva la 95%, ceea ce este foarte bine. Dacă acuratețea este slabă, putem presupune că modelul este nesatisfăcător și că avem nevoie de mai multe features pentru a incorpora datele relevante sau că avem nevoie de mai multe date. Dacă performanța este slabă la validarea făcută pe datele de antrenament, nu putem să așteptăm performanțe bune pe datele de testare (care, așa cum spuneam la început, sunt date care nu au fost implicate în procesul de antrenare).
Reducerea dimensionalității (Dimensionality Reduction)
Intuiția ne spune că, din perspectiva modelului de predicție machine learning, avem nevoie de cât mai multe features posibile, dar din perspectiva performanței, avem nevoie de cât mai puține features, însă nu mai puține de cât e necesar pentru obținerea unui model bun care să rezolve problema. Într-adevăr, uneori, un model de machine learning mai rapid este preferabil unuia mai performant. Matricea de corelație (pentru mai multe detalii consultați prima parte a acestei serii de articole) este doar o manieră de a decide ce features trebuie păstrate pentru modelele de clasificare și de regresie, o altă metodă fiind PFI (Permutation Feature Importance).
PFI (Permutation feature importance)
Permutând aleatoriu datele din setul de date, feature cu feature, măsurăm importanța unui feature calculând creșterea erorilor modelului de predicție după permutarea acelui feature. Cu cât schimbarea produsă e mai mare, cu atât mai important este feature-ul. Astfel, putem selecta cele mai importante features (concentrându-ne pe utilizarea unui subset de features ce au semnificație mai mare) pentru a construi modelul nostru. Astfel, putem reduce zgomotul din datele noastre și timpul de antrenare a modelului.
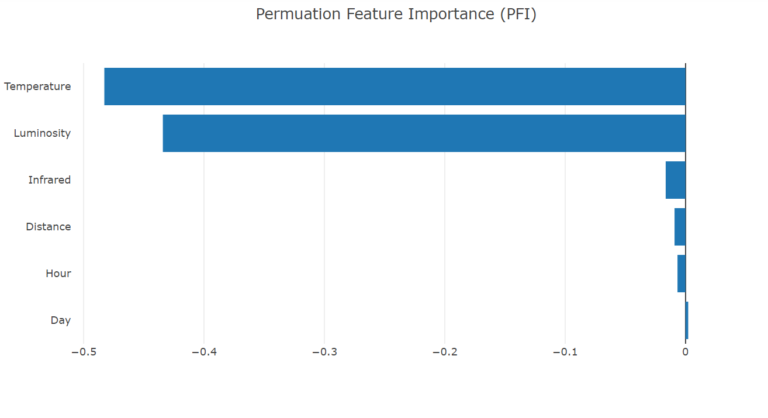
Adăugând un feature cu o corelație puternică, ne așteptăm ca importanța feature-ului asociat să scadă.
În imaginea de mai sus, putem observa că Day și Hour, poate și Distance, pot fi înlăturate fără impact major asupra performanței modelului.
var transformedData = model.Transform(trainingData);
var linearPredictor = model.LastTransformer;
var permutationMetrics = mlContext.MulticlassClassification.PermutationFeatureImportance(linearPredictor, transformedData);Evaluați modelul
Metricile de evaluare sunt similare celor folosite la validare, dar sunt foarte diferite din perspectiva datelor pe care se acționează. Astfel, evaluarea se realizează pe setul de date de test (date nefolosite până acum), care a fost pus deoparte când am împărțit setul de date original. Setul de date de test nu a fost implicat în procesul de antrenament. Putem spune că un model este extrem de specific (overfitting) dacă are rezultate bune pe setul de date de antrenament, dar rezultate rele pe setul de date de test.
var predictions = model.Transform(testingData);
var metrics = mlContext.MulticlassClassification.Evaluate(predictions, "Label", "Score", "PredictedLabel");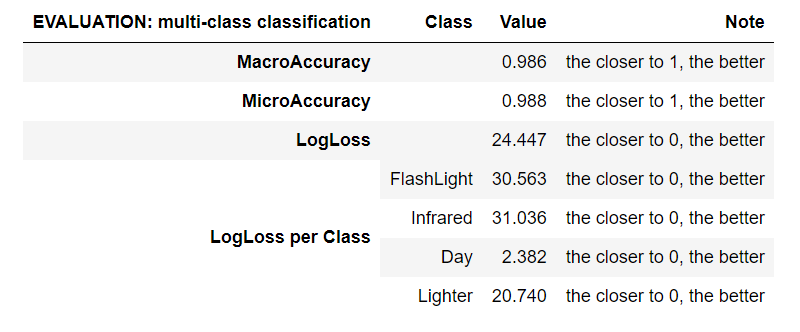
Normalizarea
Primul impuls este de a considera că impactul sau ponderea asupra modelului a fiecărui feature este același. Indiferent de tip (text, categorii, numere sau valori adevărate sau false) pentru machine learning toate aceste date sunt doar numere și, evident, valorile aflate în intervale diferite vor avea impact diferit. Prin urmare, datele trebuie normalizate, pentru a aduce valorile în același interval. Dacă nu normalizăm feature-urile riscăm să antrenăm un model slab, neperformant.
Unii traineri nu au nevoie de normalizare explicită- normalizarea este implicită la nivel de feature-, pe când alții au nevoie. Din fericire, nu trebuie să cunoaștem algoritmul pentru a decide acest lucru, deoarece putem găsi descrierea fiecărui trainer în documentația oficială.
Caracteristicile componentei trainer
| Machine learning task | Multiclass classification |
|---|---|
| Is normalization required? | Yes |
| Is caching required? | No |
| Required NuGet in addition to Required Nu | None |
| Exportable to ONNX | Yes |
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.CustomMapping(CustomMappings.IncomeMapping, nameof(CustomMappings.IncomeMapping)))
.Append(mlContext.Transforms.Concatenate("Features", featureColumns))
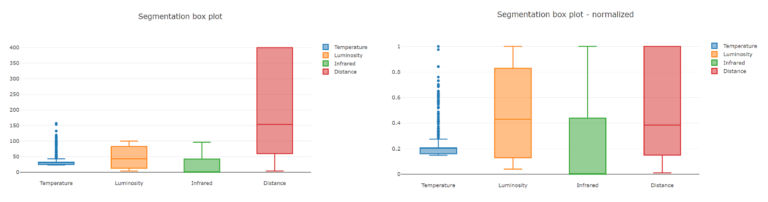
.Append(mlContext.Transforms.NormalizeMinMax("Features"));Să analizăm diagramele de mai jos înainte și după normalizare. Apoi să comparăm Distance cu Temperature. Feature-ul Distance din partea stângă a imaginii va avea un impact mai mare asupra modelului (pentru că ne aflăm înainte de normalizare), însă cel din partea dreaptă a imaginii este echilibrat.
Metrici de evaluare
Micro-acuratețea (Micro-Accuracy) agregă contribuțiile tuturor claselor pentru a calcula valorile medii. Cu cât valoarea este mai apropiată de 1.00, cu atât mai bine. În cadrul unei sarcini de clasificare pe clase multiple, micro-acuratețea este preferabilă macro-acurateții dacă suspectați că aveți clase neechilibrate.
Macro-acuratețea (Macro-Accuracy) este acuratețea medie la nivel de clasă. Se calculează acuratețea fiecărei clase, iar macro-acuratețea este media acestor nivele de acurateță. Cu cât valoarea este mai apropiată de 1.00, cu atât mai bine.
Log-Loss măsoară performanța unui model de clasificare unde datele de intrare pentru predicție au o probabilitate cu valoare între 0.00 și 1.00. Cu cât valoarea este mai apropiată de 0.00, cu atât mai bine. Scopul modelelor noastre de machine learning este minimizarea acestei valori.
Log-Loss reduction poate fi interpretată drept avantajul clasificatorului asupra unei predicții aleatorii. În cadrul intervalelor from -inf și 1.00, 1.00 reprezintă predicții perfecte și 0.00 indică predicțiile mediilor. De exemplu, dacă valoarea este egală cu 0.20, interpretarea este că “probabilitatea unei predicții corecte este cu 20% mai bună decât o predicție aleatorie”.
Matricea de confuzie
Pe lângă micro-acuratețe, macro-acuratețe și log-loss, putem măsura și matricea de confuzie, care este un tabel ce descrie performanța modelului per categorii. Folosind setul de date de test putem face predicții, putem compara rezultatele prezise cu rezultatele reale pentru fiecare categorie și le putem aranja într-o matrice de confuzie.
var metrics = mlContext.MulticlassClassification.Evaluate(predictions, Label, Score, PredictedLabel);
Console.WriteLine(metrics.ConfusionMatrix.GetFormattedConfusionTable());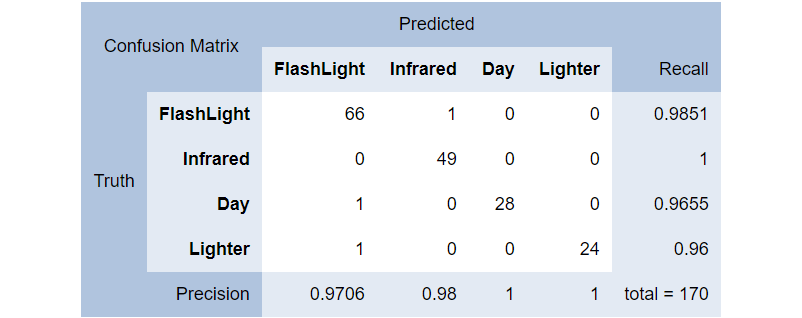
În diagrama precedentă, putem observa clasa FlashLight care a fost prezisă corect (drept FlashLight source) de 66 de ori și incorect drept Day 1 dată și Lighter 1 dată, rezultând într-o rată de precizie de 0.9706 sau 97.06%.
Recall sau gradul de sensibilitate este o altă modalitate de a măsura calitatea modelului nostru. De exemplu, Infrared este prezis corect drept FlashLight o singură dată, ceea ce ne oferă o precizie de 98% pentru un grad de sensibilitate de 100%. Într-un alt exemplu, Day este prezis corect 100%, dar sensibilitatea este doar 96.55%, ceea ce nu este atât de rău!
Salvați modelul
După ce am experimentat cu diferite seturi de features, trainers și parametri, pentru construirea unui model de machine learning, alegem experimentul care se potrivește cel mai bine nevoilor noastre. Cel mai probabil, avem nevoie de acest model într-un scenariu de producție, deci trebuie ca modelul să fie salvat într-o formă persistentă, anume într-un fișier în format fizic ML.NET sau format ONNX (un format portabil dezvoltat de Microsoft și Facebook și adoptat de mulți alții). Nesurprinzător, dacă ne uităm la fișierele modelului nativ ML.NET, remarcăm că este un zip cu fișiere text ce conțin numere (ponderi și erori, sau coeficienți).
Salvați modelul în format nativ:
mlContext.Model.Save(model, trainingData.Schema, MODEL_PATH);Salvați modelul în format ONNX:
using (var stream = System.IO.File.Create(ONNX_MODEL_PATH))
{
mlContext.Model.ConvertToOnnx(model, trainingData, stream);
}Modelați componenta Re-train
În ceea ce privește performanța de timp, antrenamentul unui model este un proces costisitor. Când antrenăm un model cu mai multe date, modelul devine mai bun, dar ce ar trebui să facem după ce modelul este construit? Ar trebui să îl reconstruim de la început cu setul nou de date, mai mare? Răspunsul este NU. Putem să adăugăm oricând date noi (acest lucru se poate face doar pentru trainers reantrenabili!) într-un model existent, iar apoi să îl reantrenăm.
Pentru a reantrena un model, trebuie să extragem parametrii din modelul original, ce reprezintă punctul de plecare al noului model, și să apelăm metoda Fit cu noul set de date și cu parametrii originali.
Încărcarea modelului original se face astfel:
var model = mlContext.Model.Load("model.zip", var out modelSchema);Putem extrage parametrii originali și să pregătim noul set de date:
var originalModelParameters = ((ISingleFeaturePredictionTransformer) model).Model as LinearMulticlassModelParameters;
var transformedNewData = preprocessingPipeline.Transform(newData);Apoi reantrenăm modelul:
var retrainedModel = mlContext.MulticlassClassification.Trainers.SdcaNonCalibrated("Label", "Features")
.Fit(transformedNewData, originalModelParameters);Acum că avem un model machine learning, vom trece la predicții în următorul articol.
2 thoughts on “[Romanian] Machine Learning 101 cu Microsoft ML.NET (partea 2/3)”