
The purpose of this series of articles is to provide a complete guide (from data to predictions) to machine learning, for .NET developers in a .NET ecosystem, and that is possible now using Microsoft ML.NET and Jupyter Notebooks. Even more, you don’t have to be a data scientist to do machine learning.
1. What is Machine Learning?
The traditional way of programming, having the developers designing the steps of the algorithms, is not going to be replaced by machine learning. The old existing paradigms are safe, but, as always, there is space for evolving.
Machine Learning (ML) is not even new, but now, thanks to the technological advance (like faster CPUs and GPUs, memories, and dedicated hardware) and the exponential growth of available data, is the time for ML to become broadly adopted by developers.
Let me state a few facts about Machine Learning. If traditional programming is like a step-by-step recipe for a cake, Machine Learning is like a trial-and-error way of doing a cake. Instead of previously knowing the steps (algorithm) of how the ingredients should be mixed to get the cake, a lot of cake recipes are measured (classified, rated, etc.) along with their ingredients. The human mind is doing exactly the same! Either having a previously invented recipe or either learning a new one on-the-fly. Of course, in the case of having a previously invented recipe let’s not forget that someone has to naturally (opposing to artificially) invent the recipe first.
Now let’s assume the cake recipe is an algorithm. On a side, traditional programming is like instructing the machine how to run an algorithm (invented by the human mind) on input data to get output data. On the other side, machine learning is learning an artificial algorithm using only input and output data, and then the newly created algorithm has to be run on the input data, in order to get output data (sounds familiar?).
Machine learning is not a general panacea for solving problems, actually, we have to choose very carefully when to use ML, but it’s true there are a lot of problems impossible or very hard to solve in a traditional way.
Decisions decisions
Let’s demystify Machine Learning a little. As I have mentioned above, machine learning is basically an algorithm, code consisting of decisions (if-else). The more decisions we have, the more complex it gets to code, but while for a machine dealing with dozens or hundreds of variables this is not a problem, for the human mind it gets quickly very hard to control (design or maintain). In conclusion, machine learning is an algorithm written by the machine, instead of an algorithm invented by a human mind. Is that simple? Not really. The algorithm invented by the machine is rather an approximation, which solves a problem, therefore the accuracy is more or less precise. But it’s the same with human intuition, isn’t it? When you spot a shadow running towards you in a jungle, you are happy enough with an 80% probability the shadow is a tiger or an enemy, to get you running for your life. Live enough to check later if it’s true or not. This is not happening usually with traditional programming.
Machine Learning is not even fast, because the learning process takes a lot. The more data you have for training, the longer is the training process. (Do not get confused here, training the model is different from consuming the model, but again, consuming the model is much faster, like running a regular algorithm). On the other side, a machine learning model is agile, just think about the effort invested in rewriting complex algorithms, in traditional programming. A machine learning model (and its algorithm) is rewritten by retraining it.
Now really, why Machine Learning?
Machine Learning is as good as its data, which means a bad dataset drives to a bad machine learning model. Then why do we need machine learning? Because machine learning is a way of modeling the part of our human intelligence based on learning, transmitting the experiences, intuition, etc. Therefore machine learning helps us make machines more human.
2. Is Microsoft ML.NET yet another machine learning framework?
When thinking of data science and machine learning, Python programming language is making the rules. In addition to that, the existing frameworks like TensorFlow, Keras, Torch, CoreML, CNTK, are not easy to integrate with .NET projects.
Worry no more, ML.NET is designed for .NET developers and as a developer, you have access to the entire lifecycle of a machine learning model. You can prepare the data, train, and build your model, validate, evaluate, and consume the model, and you can do that on-premise and in-process! I truly value the cloud, but I think on-premise will never die. Add to all these the cross-platform, open-source, and .NET Core heart and you will get a very promising framework.
ML.NET is built upon .NET Core and .NET Standard (inheriting the ability to run on Linux, macOS, and Windows) and it’s designed as an extensible platform, therefore you can consume models created with other popular ML frameworks (TensorFlow, ONNX, CNTK, Infer.NET). Microsoft ML.NET is more than machine learning, it includes deep learning, and probabilistic and you have access to a large variety of machine learning scenarios, like image classification, object detection.
Prepare ML environment
Normally I would ask you to install Visual Studio 2017 15.9.12 or later or Visual Studio Code with .NET Core SDK 2.1 or later, but you can also use Jupyter Notebooks.
There are several ways to get started using .NET with Jupyter. See the Installation guide for .NET Interactive. If you want to run Jupyter Notebooks locally, you have to install Jupyter Notebook on your machine using Anaconda following the installation guide for .NET Interactive.
If you have successfully installed Jupyter Notebook you can launch it from the Windows menu to open or create a notebook.
3. Prepare the data
A good dataset is better than a smart algorithm, in other words, your model cannot be better than your dataset. Be very careful when preparing the data, because your data DNA contains all kinds of biases we want to avoid.
Until recently, maybe the weakest part of ML.NET was data analysis. Creating a model is an iterative process, and you have to experience a lot with transformers and trainers, measuring and improving the model many times, or tweaking the hyperparameters. During the process you need to analyze the data, again and again, ideally in a visual way. Python users have Jupyter Notebooks which is a great tool where you can integrate the markdown information, with code and with diagrams, and now, .NET developers can run on-premise interactive machine learning scenarios with Jupyter Notebooks using with C# or F#, in a web browser.
Data pipelines
Data preparation and training are done using pipelines and the outcome is a model. A pipeline consists of a sequence of transformers and estimators, called in a fluent way. We can start by loading data, then making some data transformations, and eventually calling the estimators to get a model. Later, the model is called with new data to make predictions.
Transformers are responsible for data preprocessing and postprocessing and for applying imported models in ONNX or TensorFlow format. Transformers take a DataView as input and output a DataView.
Estimators are responsible for model training.
In fact, data loaders, transformers, savers, trainers, estimators, predictors, etc., are all working with DataView related components. DataView object is schematized (each column has a name, type, metadata), in-memory, immutable, lazy, and composable (new views are formed by applying transformations on other views).
Defining a practical scenario
Let’s suppose we have a system able to read temperature, luminosity, infrared, and distance to a source (of previously enumerated energy types) and we have a dataset consisting of a few hundred observations. These observations are labeled, which means we have a source for every observation in the dataset. We want to predict the source for a new observation.
In order to do that, we have to:
- load the data
- preprocess the data* (build a data pipeline)
- build the training pipeline
- postprocess the data
- evaluate the model
- train the model
- validate the model
- predict new data
* we might need a preprocessing pipeline to prepare the data, by building a data pipeline to:
- clean data (removing duplicates, irrelevant data, fixing typos, inconsistent capitalization, filter unwanted outliers, handle missing data)
- feature engineering (combine features, combine sparse classes, remove unused features)
- identify categorical data
- normalize data
- shuffle data
- split data in train and test subsets
Depending on the task we want to solve we can skip some of the above steps.
Feature Engineering
Feature engineering is about creating new features from existing ones to improve model performance and Feature selection is not the same as feature engineering.
A new feature can be created:
- from two or more features by an interaction like sum, difference, product. For example, we have one feature infected, the number of viral infections per region, and another feature population, the total population of a region. It might be more important to have a feature like infection_rate as infected / population.
- combining sparse classes into a more robust one. It applies to categorical features having too few observations.
- Converting a string feature to numerical binary features using onehotencoding
- drop unused features
Let’s get our hands dirty
The following code (marked as code) blocks can be copied and run as code cells in Jupyter Notebook.
From the very first line you might want to install nuget packages and call some libraries in the notebook, but you can do that anywhere in the notebook.
#r "nuget:Microsoft.ML,1.4.0"
using System;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Data;
using XPlot.Plotly;Obviously enough, Microsoft.ML packages are related to ML.NET. Xplot.Plotly, one of the most important features of Jupyter, is a data visualization library responsible for rendering amazing diagrams.
Let’s instantiate the ML context which we will use to call the needed catalogs, transformers, estimators, predictors, and more.
private static readonly MLContext mlContext = new MLContext(seed: 123);Declare an input data model for our dataset.
public class ModelInput
{
[ColumnName("Temperature"), LoadColumn(0)]
public float Temperature { get; set; }
[ColumnName("Luminosity"), LoadColumn(1)]
public float Luminosity { get; set; }
[ColumnName("Infrared"), LoadColumn(2)]
public float Infrared { get; set; }
[ColumnName("Distance"), LoadColumn(3)]
public float Distance { get; set; }
[ColumnName("CreatedAt"), LoadColumn(4)]
public string CreatedAt { get; set; }
[ColumnName("Label"), LoadColumn(5)]
public string Source { get; set; }
}Load some structured (having a schema deserializable into ModelInput) data from a csv file using the ML context.
private const string DATASET_PATH = "./sensors_data.csv";
IDataView data = mlContext.Data.LoadFromTextFile<ModelInput>(
path: DATASET_PATH,
hasHeader: true,
separatorChar: ',');We need to shuffle the data and split it into two categories, training data and testing data, by a ratio of 4:1 (a subset of 70-90% is recommended to go to the training dataset and the rest of 10-30% to testing dataset).
var shuffledData = mlContext.Data.ShuffleRows(data, seed: 123);
var split = mlContext.Data.TrainTestSplit(shuffledData, testFraction: 0.2);
var trainingData = split.TrainSet;
var testingData = split.TestSet;DataView trainingData is not directly accessible so we might want to create a collection from it and to display it using the display command. Let me get into the details. In a Jupyter Notebook, we can use Console.WriteLine to print data, but we will love the display command since it’s able to print text, html, svn, and charts, using DataFrame. Let’s be careful not to display the entire dataset so we can use Take(10) to fetch the first 10 observations.
var features = mlContext.Data.CreateEnumerable<ModelInput>(trainingData, true);
display(features.Take(10));
We can notice a few special elements in the image above. An observation is a reading, a row with a set of features. The features are variables in the dataset identified as columns. A label or a target variable is a special kind of feature we are trying to predict. Any feature can be a label depending on the problem we are solving.
In the next formula, the x values are the features and f is our model which predicts the label Y.
Y = f(x1, x2, …xn)
Of course, we don’t understand much looking at the tabular data but Jupyter brings up some great diagram types with XPlot.Plotly library, which can aggregate the data in a more useful way.
We might need to see the categories.
var categories = trainingData.GetColumn<string>("Label");
var categoriesHistogram = Chart.Plot(
new Graph.Histogram { x = categories }
);
display(categoriesHistogram);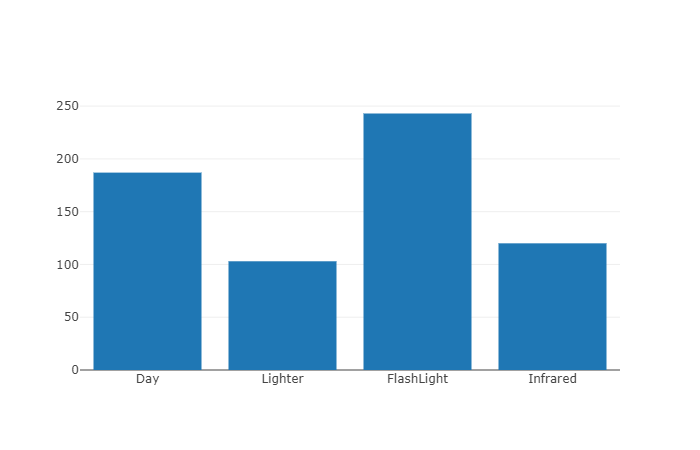
Plot segmentation
If we need to see more information about our data we can use plot segmentation.
var featuresTemperatures = features.Select(f => f.Temperature);
var featuresLuminosities = features.Select(f => f.Luminosity);
var featuresInfrareds = features.Select(f => f.Infrared);
var featuresDistances = features.Select(f => f.Distance);
var featuresDiagram = Chart.Plot(new[] {
new Graph.Box { y = featuresTemperatures, name = "Temperature" },
new Graph.Box { y = featuresLuminosities, name = "Luminosity" },
new Graph.Box { y = featuresInfrareds, name = "Infrared" },
new Graph.Box { y = featuresDistances, name = "Distance" }
});
display(featuresDiagram);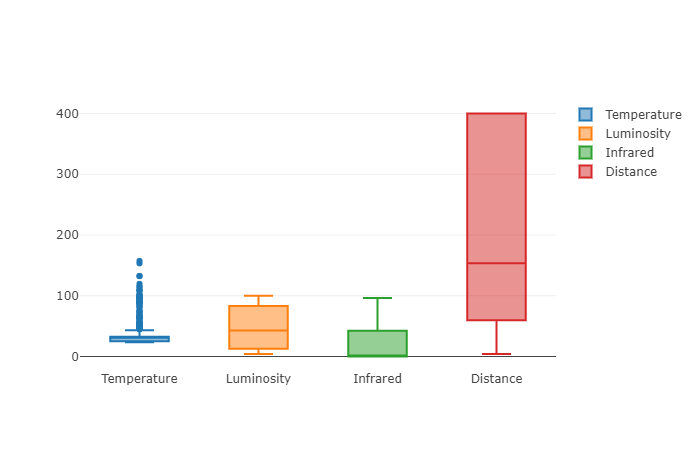
Looking at the diagram we can extract valuable information like:
- the median bar from Distance is much higher compared to the other features
- the min-max values from Temperature and Infrared are not uniformly distributed
- Temperature has many outliers
We can use this information later to improve the model accuracy.
To prepare the data, we have to remember that we deal with a machine and we have to transform all categorical data (strings) into numbers using categorical transformers like OneHotEncoding.
Correlation Matrix
Thinking of data, another question arises, do we really need all the features? Most probably some are less important than others. The correlation matrix is an excellent instrument able to measure the correlation between the features as it follows:
- near -1 or 1 indicates a strong relationship (proportionality).
- closer to 0 indicates a weak relationship.
- 0 indicates no relationship.
The following piece of code might look messy but we need to prepare the data for the correlation matrix, it’s nothing more than aligning the values in pairs and calling Correlation.Pearson function on them.
#r "nuget:MathNet.Numerics, 4.9.0"
using MathNet.Numerics.Statistics;
var featureColumns = new string[] { "Temperature", "Luminosity", "Infrared", "Distance" };
var correlationMatrix = new List<List<double>>();
correlationMatrix.Add(featuresTemperatures.Select(x => (double)x).ToList());
correlationMatrix.Add(featuresLuminosities.Select(x => (double)x).ToList());
correlationMatrix.Add(featuresInfrareds.Select(x => (double)x).ToList());
correlationMatrix.Add(featuresDistances.Select(x => (double)x).ToList());
var length = featureColumns.Length;
var z = new double[length, length];
for (int x = 0; x < length; ++x)
{
for (int y = 0; y < length - 1 - x; ++y)
{
var seriesA = correlationMatrix[x];
var seriesB = correlationMatrix[length - 1 - y];
var value = Correlation.Pearson(seriesA, seriesB);
z[x, y] = value;
z[length - 1 - y, length - 1 - x] = value;
}
z[x, length - 1 - x] = 1;
}Now let’s render the correlation matrix.
var correlationMatrixHeatmap = Chart.Plot(
new Graph.Heatmap
{
x = featureColumns,
y = featureColumns.Reverse(),
z = z,
zmin = -1,
zmax = 1
}
);
display(correlationMatrixHeatmap);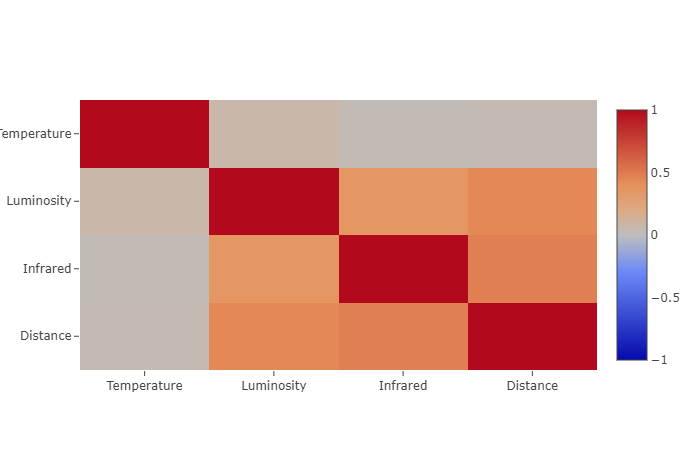
The strongly correlated features do not convey extra information (they are influenced too much on each other), therefore you can remove the one that has a larger mean absolute correlation with other features (it’s not the case here, we need them all).
For example, our most correlated features are Distance and Infrared (0.48), and Temperature seems to be the most uncorrelated feature compared with any other features.
Build the preprocessing pipeline
By convention, ML.NET is expecting to find the Features column (as input) and Label column (as output), if you have such columns, you don’t have to provide them, otherwise, you have to do some data transformations to expose these columns to the transformers.
Also, if we need to do binary or multi-classification, we have to convert the label to numbers using MapValueToKey.
In most cases we have more than one relevant feature we might need to train our model and we need to concatenate them into the previously mentioned feature named Features.
var featureColumns = new string[] { "Temperature", "Luminosity", "Infrared", "Distance" };
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.Concatenate("Features", featureColumns));Now we have a data preprocessing pipeline and we are ready to build the model in part 2 of this series.
1 thought on “Machine Learning 101 with Microsoft ML.NET (part 1/3)”
Comments are closed.