
Este Microsoft ML.NET (doar) un alt framework de machine learning?
În lumea data science și a machine learning, limbajul de programare Python face regulile. În plus, framework-urile existente precum TensorFlow, Keras, Torch, CoreML, CNTK, nu sunt ușor de integrat cu proiectele .NET.
Framework-ul ML.NET este bazat pe .NET Core și .NET Standard (moștenind capacitatea de a rula pe Linux, macOS și Windows) și este conceput ca o platformă extensibilă, deci se pot consuma modele create cu alte framework-uri populare cum sunt: TensorFlow, ONNX , CNTK, Infer.NET. Microsoft ML.NET este mai mult decât machine learning, include deep learning și probabilistica și aveți acces la o mare varietate de scenarii de deep learning, cum ar fi clasificarea de imagini sau detectarea de obiecte.
Este Microsoft ML.NET ușor de utilizat?
Utilizatorii Python au la dispoziție mediul interactiv Jupyter Notebook, care este un instrument excelent în care puteți integra text (compatibil markdown), cod și diagrame.
Până de curând ML.NET nu avea un instrument REPL (read-eval-print-loop) pentru a lucra cu interactiv cu cod și date, dar acum, dezvoltatorii .NET pot rula scenarii interactive de machine learning (și nu numai!) cu Jupyter Notebook folosind C #, F # sau Powershell într-un browser web.
Instalarea Jupyter Notebook
Există mai multe moduri de a folosi Jupyter Notebook cu .NET. Dacă doriți să rulați Notebook Jupyter local, trebuie să instalați Jupyter Notebook folosind Anaconda (distribuție de Python pentru data science). Dacă ați instalat cu succes Jupyter Notebook, îl puteți lansa din Windows pentru a deschide / crea un notebook. Mai multe detalii aici: https://devblogs.microsoft.com/dotnet/net-interactive-is-here-net-notebooks-preview-2/
Definirea unui scenariu practic
Să presupunem că avem un sistem capabil să măsoare temperatura, luminozitatea, radiația infraroșie și distanța până la o sursă de energie (sursa poate fi o lanternă, o bricheta, lumina ambientală sau o lanternă cu radiație infraroșie). Măsurătorile se fac cu ajutorul unor senzori conectați la un dispozitiv IoT (Raspberry Pi 3) și avem un set de date format din câteva sute de observații. Aceste observații sunt etichetate (labeling), ceea ce înseamnă că avem sursa fiecărei observații din setul de date. Cu alte cuvinte, vrem să prezicem sursa pentru fiecare nouă observație.
Să analizăm un document Jupyter Notebook
Una dintre cele mai importante caracteristici ale Jupyter Notebook, XPlot.Plotly, este o bibliotecă excelentă de vizualizare a datelor, responsabilă de randarea diagramelor.
Să presupunem că am inclus dependințele, am inițializat contextul ML și am încărcat seturile de date pentru antrenarea modelului (training) și pentru testarea modelului (testing).
#r "nuget:Microsoft.ML,1.4.0"
using Microsoft.ML;
using Microsoft.ML.Data;
using XPlot.Plotly;
private static readonly MLContext mlContext = new MLContext(2020);Comanda “display”
Într-un document Jupyter Notebook putem folosi Console.WriteLine pentru a afișa date, dar comanda display este net superioară, deoarece este capabilă să afiseze text, html, svn și diagrame.
var features = mlContext.Data.CreateEnumerable<ModelInput>(trainingData, true);
display(features.Take(10));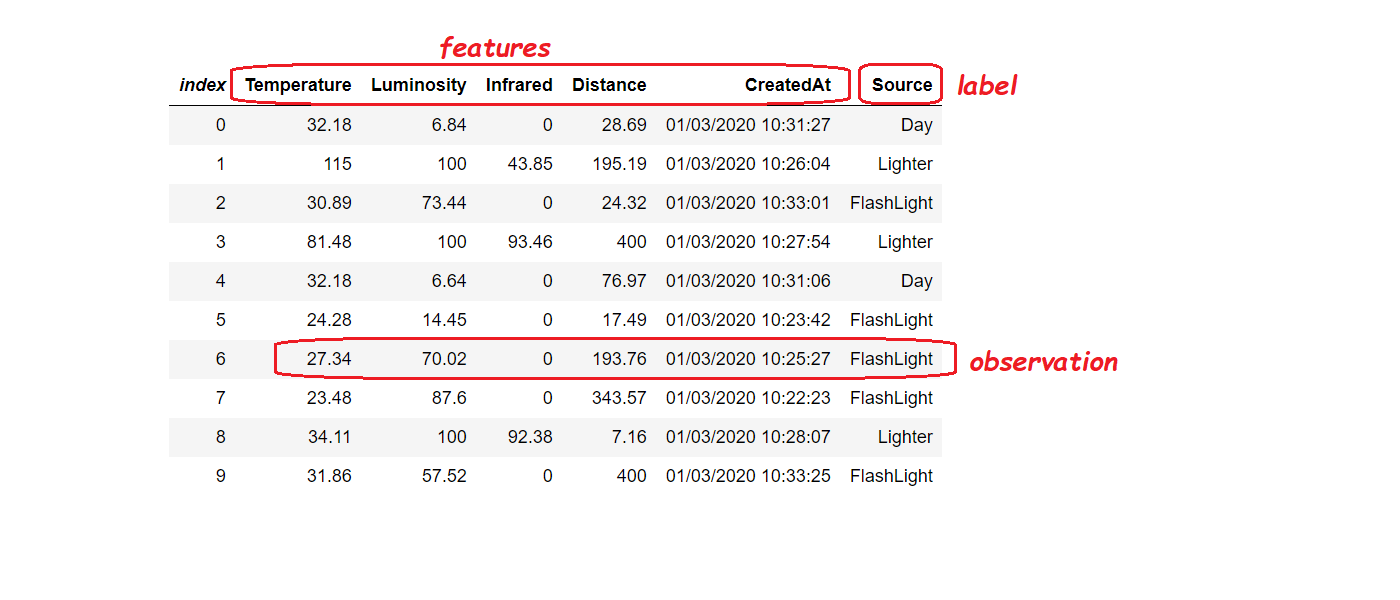
Bineînțeles că nu înțelegem foarte mult privind datele în forma lor tabulară, dar Jupyter Notebook aduce câteva tipuri de diagrame excelente prin biblioteca XPlot.Plotly, care este capabilă să agregheze datele într-un mod mult mai informativ.
Segmentarea Box Plot
Dacă dorim să aflăm mai multe informații despre datele noastre, putem folosi un alt tip de diagramă, segmentarea box plot.
var featuresDiagram = Chart.Plot(new[] {
new Graph.Box { y = featuresTemperatures, name = "Temperature" },
new Graph.Box { y = featuresLuminosities, name = "Luminosity" },
new Graph.Box { y = featuresInfrareds, name = "Infrared" },
new Graph.Box { y = featuresDistances, name = "Distance" }
});
display(featuresDiagram);
Privind diagrama putem extrage informații valoroase, cum sunt:
- bara mediană a Distanței este poziționată mult mai sus comparativ cu celelalte măsurători (features), cum sunt Luminozitatea, Temperatura sau Infraroșu
- valorile min-max pentru Temperatură și Infraroșu nu sunt distribuite uniform
- Temperatura are multe valori periferice (care, în anumite situații, pot fi citiri eronate, dar nu în mod necesar)
Mai târziu, putem utiliza aceste informații pentru a îmbunătăți exactitatea modelului, dar acum există un alt lucru care ne atrage atenția, unele măsurători (features), cum ar fi Distanța, par să cântărească „mai greu” decât celelalte. Să vedem ce se întâmplă dacă încercăm să le aducem pe toate la aceeași scară sau, cu alte cuvinte, să le normalizăm.
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.CustomMapping(parseDateTime, null))
.Append(mlContext.Transforms.Concatenate("Features", featureColumns))
.Append(mlContext.Transforms.NormalizeMinMax("Features", "Features"));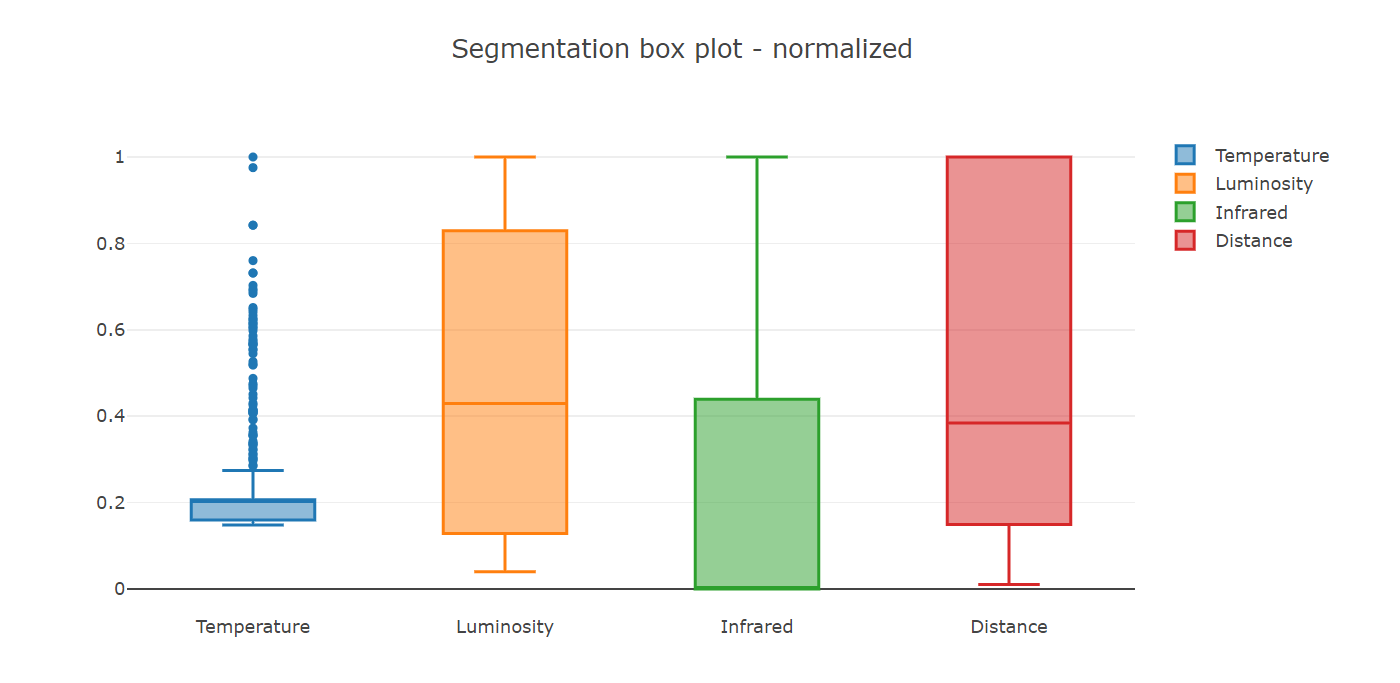
Măsurătorile (features) sunt acum normalizate, iar influența lor asupra modelului care va fi antrenat este echilibrată.
Matricea de Corelație
Privind datele, apare o altă întrebare: Chiar avem nevoie de toate măsurătorile? Cel mai probabil, unele sunt mai puțin importante decât celelalte. Matricea de corelație este un instrument capabil să măsoare corelația dintre coloane sau măsurători (features), două câte două, după cum urmează:
- O valoare apropiată de -1 sau 1 indică o relație puternică (proporționalitate).
- O valoare mai aproape de 0 indică o relație slabă.
- O valoare egală cu 0 indică lipsa unei relații.
#r "nuget:MathNet.Numerics, 4.9.0"
using MathNet.Numerics.Statistics;
var correlationMatrixHeatmap = Chart.Plot(new Graph.Heatmap { x = featureColumns, y = featureColumns.Reverse(), z = z, zmin = -1, zmax = 1 });
display(correlationMatrixHeatmap);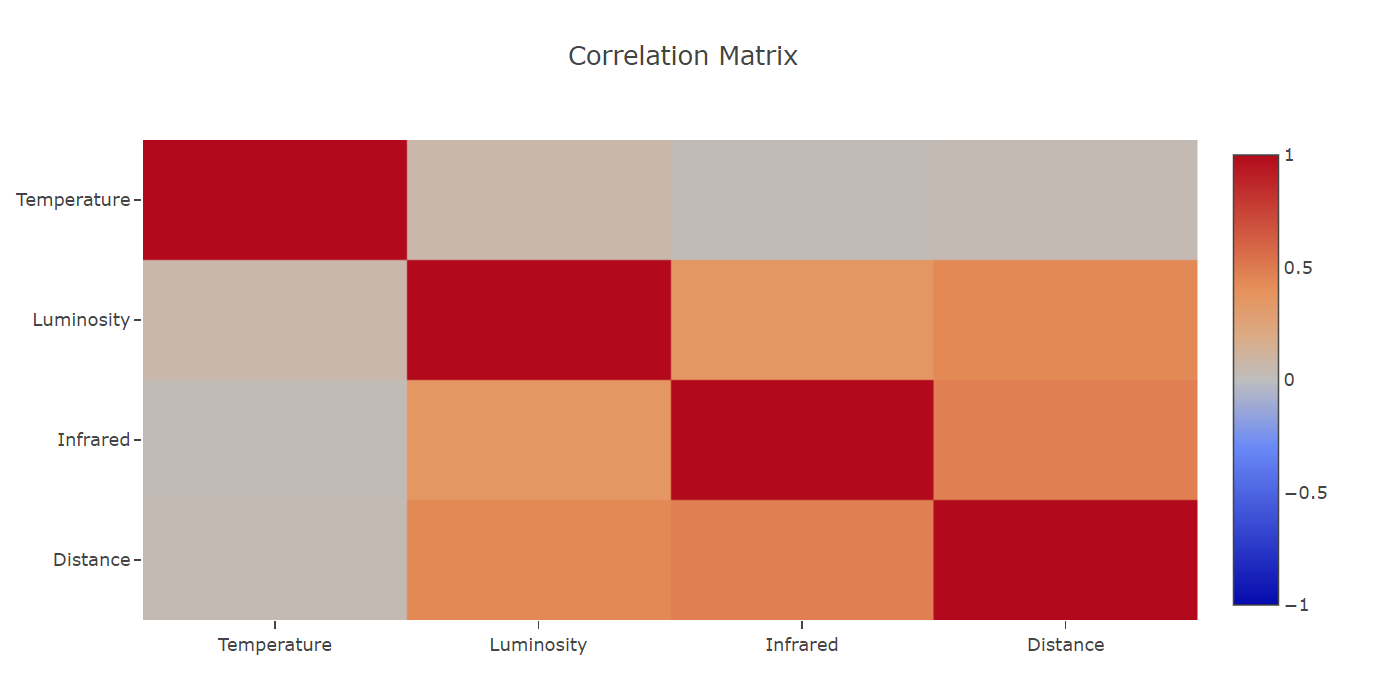
Două măsurători puternic corelate nu transmit informații suplimentare, de aceea una dintre ele poate fi eliminată (nu este cazul aici!).
De exemplu, caracteristicile noastre cele mai corelate sunt Distanța și Infraroșu (0,48), iar Temperatura pare să fie cea mai “necorelată” în comparație cu celelalte.
Pregătirea pipeline-ului de preprocesare
Prin convenție, ML.NET caută în pipeline coloana “Features” (input) și coloana “Label” (output), însă dacă avem aceste coloane, nu mai trebuie să le furnizăm, altfel trebuie să facem unele transformări pe date pentru a obține și expune aceste coloane.
În plus, dacă folosim pentru construirea modelului o clasificare binară sau multiplă, trebuie să transformăm coloana “Label” într-un număr folosind MapValueToKey (pentru că machine learning lucrează intern doar cu numere!).
var featureColumns = new string[] { "Temperature", "Luminosity", "Infrared", "Distance" };
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.Concatenate("Features", featureColumns));În cele mai multe cazuri, avem mai multe coloane (măsurători) relevante pe care vom dori să le concatenăm într-una singură, numită “Features”.
Construirea și antrenarea modelului
În sfârșit, avem tot ce ne trebuie să construim modelul și să îl antrenăm, folosind unul dintre algoritmii de multi-clasificare, Stochastic Dual Coordinate Ascent (SDCA), însă am putea dori să încercăm și alți algoritmi.
var modelPipeline = preprocessingPipeline.Append(mlContext.MulticlassClassification.Trainers.SdcaNonCalibrated("Label", "Features"));
var postprocessingPipeline = modelPipeline.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
var model = postprocessingPipeline.Fit(trainingData);Matricea de confuzie
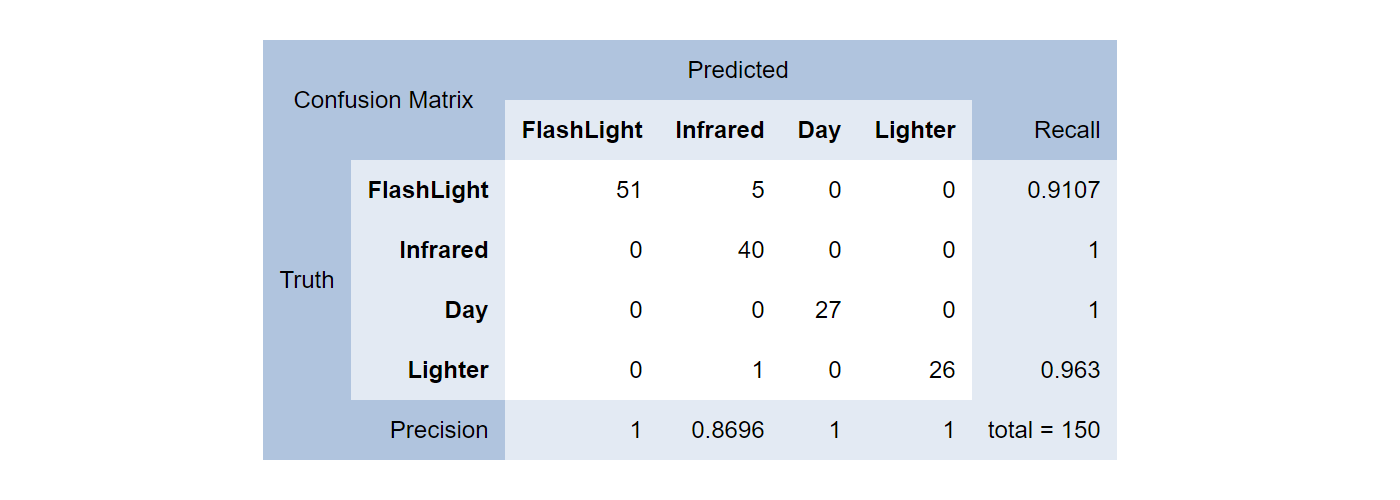
După ce am obținut un model, primul lucru de care trebuie să ne preocupăm este performanța modelului, iar Matricea de confuzie este o măsurare excelentă a performanței pentru machine learning în cazul clasificării.
Folosind setul de date de testare putem face predicții și putem compara rezultatele preconizate cu rezultatele reale. În diagrama următoare putem vedea că clasa Infraroșu a fost prezisă corect (ca Infraroșu) de 40 de ori, a fost prezisă incorect ca FlashLight de 5 ori, și incorect ca Lighter o singură dată, rezultând o rată de precizie de 0,8696.
Importanța caracteristicilor de permutare
Un alt instrument util este diagrama PFI (Permutation Feature Importance). PFI calculează scorul de importanță pentru fiecare dintre coloane (măsurători) prin permutări aleatorii ale funcției, rezultând că unele caracteristici sunt mai mult sau mai puțin importante.
var pfi = mlContext.MulticlassClassification.PermutationFeatureImportance(linearPredictor, transformedData, permutationCount: 3);
var sortedMetrics = pfi.Select((metrics, index) => new { index, metrics.MacroAccuracy }).OrderBy(feature => Math.Abs(feature.MacroAccuracy.Mean)).Select(feature => feature.MacroAccuracy.Mean);
var pfiDiagram = Chart.Plot(new[] {
new Graph.Bar { x = sortedMetrics, y = featureColumns.Reverse(), orientation = "h", name = "Permutation Feature Importance" }
});
display(pfiDiagram);
În diagrama noastră, Distanța pare să aibă un scor foarte mic. Excluderea acestei măsurători de la construirea modelului nu va afecta semnificativ performanța modelului nostru.
Concluzie
Avem, în sfârșit, o platformă și avem un set de instrumente cu care să îmbunătățim performanța modelului nostru într-un mod iterativ. Odată ce suntem mulțumiți de precizia modelului, putem să mutăm secvența de cod care conține pipeline-ul în proiectul nostru și putem începe să facem predicții pe date noi de intrare.
Dacă doriți să experimentați cu Jupyter Notebook, îl puteți găsi la adresa: