
Scopul acestei serii de articole este de a oferi un ghid complet în Machine Learning (de la date la predicții), pentru programatori .NET ce lucrează în ecosistemul .NET. Acest lucru este posibil cu Microsoft ML.NET și Jupyter Notebooks. Mai mult, nu trebuie să fiți data scientist pentru a lucra cu machine learning.
1. Ce este Machine Learning?
Algoritmii, în mod tradițional, sunt creați de către programatori, iar acest lucru nu va fi înlocuit de Machine Learning. Paradigmele de până acum nu vor dispărea, dar, ca de obicei, există loc de îmbunătățiri.
Machine Learning (ML) nu este ceva nou, dar momentan, datorită avansurilor tehnologice (CPU mult mai rapid, GPU, memorii sau hardware specializat) și creșterii exponențiale a datelor disponibile, este momentul propice pentru ca ML să fie adoptată masiv de programatori.
Doresc să menționez câteva aspecte generale legate de Machine Learning. În timp ce programarea tradițională este precum o rețetă de prăjitură a cărei pași trebuie urmați, Machine Learning este precum a face prăjituri tot încercând și eșuând. În loc de a ști pașii dinainte (algoritmul) și de a ști cum se vor combina ingredientele pentru a obține o prăjitură, se evaluează sau se încearcă mai multe rețete de prăjituri (clasificare, rating etc.) împreună cu ingredientele lor. Mintea umană face exact același lucru, fie că e vorba de o rețetă inventată dinainte sau de una învățată din mers. Desigur, când e vorba de o rețetă invetată anterior, cineva trebuie să inventeze rețeta în mod natural (nu artificial).
Să presupunem că rețeta de prăjituri este un algoritm. Pe de o parte, în programarea tradițională, se dau instrucțiuni unei mașini ca aceasta să știe cum să ruleze un algoritm (inventat de mintea umană) pe baza datelor de intrare, astfel încât să rezulte datele de ieșire așteptate. Pe de altă parte, Machine Learning presupune învățarea unui algoritm artificial, folosind doar datele de intrare și datele de ieșire, iar apoi algoritmul rezultat trebuie să proceseze datele de intrare pentru a verifica dacă rezultă aceleași date de ieșire (Vă sună cunoscut? Ar trebui, pentru că așa funcționează mintea umană).
Machine Learning nu este un panaceu pentru rezolvarea problemelor. De fapt, trebuie să fim foarte atenți când decidem să folosim ML, dar este la fel de adevărat că sunt multe probleme care sunt fie imposibil, fie foarte greu de rezolvat în manieră tradițională.
Decizii, decizii
Să înlăturăm puțin ceața din jurul Machine Learning. Precum am menționat anterior, Machine Learning este în esență un algoritm, cod format din decizii (if-else). Cu cât avem mai multe decizii de efectuat, cu atât mai complex este codul, dar, dacă pentru o mașină ce gestionează zeci sau sute de variabile, luarea acestor decizii nu este o problemă, pentru mintea umană, procesul devine rapid greu de controlat (de realizat sau de menținut). În concluzie, Machine Learning este un algoritm scris de o mașină, în loc de a fi un algoritm inventat de mintea umană. Este oare totul atât de simplu? Nu chiar. Algoritmul inventat de mașină este mai degrabă o aproximare care rezolvă o problemă. Prin urmare, acuratețea este mai mult sau mai puțin precisă. Dar este similar intuiției umane, nu-i așa? Când observi o umbră alergând spre tine în junglă, ești mulțumit cu o probabilitate de 80% să știi că umbra este un tigru sau un inamic și să alergi pentru a-ți salva viața. Dacă mai ești în viață, poți verifica dacă a fost așa sau nu. Acest lucru nu se întâmplă în programarea tradițională.
Machine Learning nu este un proces rapid, deoarece învățarea este îndelungată. Cu cât aveți mai multe date de antrenament, cu atât mai mult durează procesul de antrenare. (Ca să nu existe confuzii, a antrena modelul este diferit de a consuma modelul, dar consumarea modelului poate fi mai rapidă decât rularea unui algoritm obișnuit). Pe de altă parte, un model de Machine Learning este Agile. Gândiți-vă ce efort mare este necesar pentru a rescrie algoritmii complexi în programarea tradițională. Un model de Machine Learning (împreună cu algoritmul său) este rescris prin reantrenarea sa, fără a modifica codul!
Totuși, ce este Machine Learning?
Un model de Machine Learning este la fel de bun precum sunt datele folosite la antrenarea sa. Un set de date prost duce la un model prost de Machine Learning. Atunci de ce avem nevoie de Machine Learning? Machine Learning este o cale de a modela o parte a inteligenței umane bazate pe învățare, de transmitere a experienței, a intuiției etc. Prin urmare Machine Learning ne ajută să facem mașinile mai umane.
2. Este Microsoft ML.NET doar o altă nouă platformă de Machine Learning?
Când ne gândim la știința datelor (data science) și Machine Learning, limbajul Python este cel ce face regulile. Pe lângă acest lucru, framework-uri curente precum TensorFlow, Keras, Torch, CoreML, CNTK nu sunt ușor de integrat în proiectele .NET.
Nu trebuie să ne mai îngrijorăm în această privință. ML.NET este un framework code-first conceput pentru programatorii .NET, iar ca programatori, aveți acces la întregul ciclu de viață al unui model de Machine Learning. Puteți pregăti datele, antrena și construi modelul vostru, valida, evalua și consuma modelul, lucruri pe care le puteți face on-premise și in-process! Apreciez foarte mult mediul cloud, dar on-premise nu va muri niciodată. Adăugați la toate acestea accesul inter-platformă, elementele open-source și .NET Core și veți obține un framework promițător.
ML.NET este construit pe .NET Core și .NET Standard (moștenind posibilitatea de a rula pe Linux, macOS, Windows), fiind o platformă extensibilă. Prin urmare, puteți consuma modele create cu alte paradigme ML populare (TensorFlow, ONNX, CNTK, Infer.NET). Microsoft ML.NET este mai mult decât Machine Learning, deoarece include deep learning, probabilități și accesul la o mare varietate de scenarii Machine Learning, precum clasificarea imaginilor sau detectarea de obiecte.
Pregătirea mediului de dezvoltare ML.NET
În mod normal, v-aș recomanda să vă instalați Visual Studio 2017 15.9.12 (sau o variantă superioară) sau Visual Studio Code cu .NET Core SDK 2.1 (sau o variantă superioară), dar puteți folosi și Jupyter Notebooks.
Sunt mai multe metode de a începe să folosiți .NET cu Jupyter. Consultați ghidul de instalare al .NET Interactive. Dacă vreți să rulați Jupyter Notebooks local, instalați Jupyter Notebook pe mașina voastră folosind Anaconda și utilizând ghidul de instalare .NET Interactive.
După ce ați instalat Jupyter Notebook, porniți-l din meniul Windows pentru a deschide și a crea un notebook.
3. Pregătirea datelor
Un set bun de date este mai bun decât un algoritm inteligent. Cu alte cuvinte, modelul vostru este la fel de bun pe cât este setul vostru de date. Fiți atenți când pregătiți datele, deoarece ADN-ul datelor voastre poate fi foarte subiectiv, iar acest lucru trebuie să-l evităm.
Până de curând, poate cea mai slabă componentă a ML.NET a fost analiza datelor. Crearea unui model este un proces iterativ și trebuie să experimentați mult cu transformarea de date și cu antrenarea modelului, măsurând și îmbunătățind modelul de multe ori, sau ajustând hiperparametrii. Pe parcursul procesului trebuie să analizați datele iar și iar, ideal într-un mod vizual. Utilizatorii Python au Jupyter Notebooks, un tool foarte bun unde se poate integra text în format markdown, cu cod și diagrame, iar acum, programatorii .NET pot rula scenarii Machine Learning interactive on-premise cu Jupyter Notebooks cu C# sau F#, într-un browser web.
Linii de procesare pentru date (Data Pipelines)
Pregătirea datelor și antrenarea modelului se realizează folosind linii de procesare (pipelines), rezultatul fiind un model. O linie de procesare este un șir de transformatori și estimatori, apelați fluent. Putem începe prin a încărca datele, iar apoi continua prin a transforma datele. La final, se apelează estimatorii pentru a obține un model. Ulterior, modelul este apelat cu date noi pentru a obține predicții.
Transformatorii sunt responsabili de preprocesarea și postprocesarea datelor, ori de importarea unor modele existente în format ONNX sau TensorFlow. Transformatorii lucrează cu DataView ca date de intrare, producând DataView ca date de ieșire.
Estimatorii sunt responsabili de antrenamentul modelului.
De fapt, componentele care încarcă datele, care transformă datele, care salvează datele, componentele care antrenează datele, precum și estimatorii, predictorii, etc., funcționează cu DataView. Un obiect DataView este schematizat (fiecare coloană are nume, tip, metadata), fiind o entitate in-memory, imutabilă, lazy-loading și compozabilă (aplicând transformări asupra obiectelor DataView se formează alte obiecte DataView).
Definirea unui scenariu practic
Să presupunem că avem un sistem capabil să citească temperatura, luminozitatea, razele infraroșii și distanța față de o sursă (de energie) și avem un set de date format din sute de observații. Aceste observații sunt etichetate, ceea ce înseamnă că avem o sursă pentru fiecare observație din setul de date. Dorim să prezicem sursa pentru o nouă observație.
Pentru a face acest lucru, trebuie să:
- Încărcăm datele
- Preprocesăm datele* (printr-o linie de procesare de date)
- Construim linia de procesare pentru antrenament
- Postprocesăm datele
- Evaluăm modelul
- Antrenăm modelul
- Validăm modelul
- Prezicem date noi
* Am putea avea nevoie de o altă linie de preprocesare a datelor prin care să:
- Curățăm datele (îndepărtarea duplicatelor sau a datelor irelevante, corectarea greșelilor de ortografie sau a scrierii cu literă mare/mică, filtrarea elementelor neuniforme, gestionarea datelor lipsă)
- Efectuăm operații asupra coloanelor (features) prin combinarea coloanelor, combinarea claselor disparate, sau îndepărtarea coloanelor neutilizate.
- Identificăm categoriile de date
- Normalizăm datele
- Permutăm datele
- Separăm datele în două seturi: unul pentru antrenarea modelului și unul pentru validarea/testarea modelului
În funcție de obiectivul nostru, putem sări peste unii dintre pașii anteriori.
Feature Engineering
Feature Engineering se referă la crearea de noi coloane (features) pe baza celor existente pentru a îmbunătăți performanța modelului.
O nouă coloană (feature) poate rezulta:
- Din 2 sau mai multe coloane (features) existente prin aplicarea de operații precum sumă, diferență, produs. De exemplu, avem o coloană (feature) numită Infectați (Infected), numărul infecțiilor virale per regiune, și o altă coloană (feature) Populație (Population), numărul total al populației unei regiuni. Ar fi mai util să avem o coloană (feature) precum rata_de_infectare calculată astfel Infectați / Populație.
- Combinând clase disparate într-o singură clasă robustă. Combinarea se aplică coloanelor (features) categoriale ce au prea puține date sau observații.
- Convertind un șir de coloane (features) text în coloane (features) binare folosind one-hot-encoding.
- Eliminarea coloanelor (features) neutilizate.
Să ne apucăm de treabă
Următoarele blocuri de cod pot fi copiate și rulate în Jupyter Notebook.
Pentru început, s-ar putea să vreți să instalați niște nuget packages și să apelați niște librării, dar puteți face acest lucru oriunde în notebook.
#r "nuget:Microsoft.ML,1.4.0"
using System;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Data;
using XPlot.Plotly;Evident, pachetele Microsoft.ML aparțin de ML.NET. Xplot.Plotly, una din cele mai importante funcționalități ale Jupyter Notebook, este o librărie de vizualizare de date responsabilă pentru redarea informațiilor sub formă de diagrame.
Să istanțiem contextul ML pe care îl vom folosi pentru a apela cataloagele necesare, transformatorii, estimatorii, predictorii și nu numai.
private static readonly MLContext mlContext = new MLContext(seed: 123);Declarați un model de date de intrare (input) pentru setul de date.
public class ModelInput
{
[ColumnName("Temperature"), LoadColumn(0)]
public float Temperature { get; set; }
[ColumnName("Luminosity"), LoadColumn(1)]
public float Luminosity { get; set; }
[ColumnName("Infrared"), LoadColumn(2)]
public float Infrared { get; set; }
[ColumnName("Distance"), LoadColumn(3)]
public float Distance { get; set; }
[ColumnName("CreatedAt"), LoadColumn(4)]
public string CreatedAt { get; set; }
[ColumnName("Label"), LoadColumn(5)]
public string Source { get; set; }
}Încărcați datele structurate (folosind ModelInput) dintr-un fișier .csv prin contextul ML.
private const string DATASET_PATH = "./sensors_data.csv";
IDataView data = mlContext.Data.LoadFromTextFile<ModelInput>(
path: DATASET_PATH,
hasHeader: true,
separatorChar: ',');Trebuie să permutăm datele și să le împărțim în două categorii (date pentru antrenarea modelului și date pentru testarea modelului), la un raport 4:1 (un subset de 70-90% din setul de date este recomandat să fie destinat antrenamentului, iar restul de 10-30% să fie destinat testelor).
var shuffledData = mlContext.Data.ShuffleRows(data, seed: 123);
var split = mlContext.Data.TrainTestSplit(shuffledData, testFraction: 0.2);
var trainingData = split.TrainSet;
var testingData = split.TestSet;Datele încărcate în DataView nu sunt direct accesibile, deci s-ar putea să dorim să creăm o colecție de date pe care să o afișăm cu funcția display. În Jupyter Notebook putem folosi Console.WriteLine pentru a afișa datele, dar funcția display ne va plăcea și mai mult deoarece poate afișa text, html, svn sau grafice, folosind DataFrame. Să avem grijă să nu afișăm întregul set de date în cazul datelor mari, ci să folosim Take(n) pentru a accesa primele “n” observații.
var features = mlContext.Data.CreateEnumerable<ModelInput>(trainingData, true);
display(features.Take(10));
Putem observa câteva elemente speciale în imaginea de mai sus. O observație este echivalentul unei citiri, un rând cu un set de valori. Coloanele (features) sunt variabile în setul de date. O etichetă (label) sau o coloană țintă este o coloană specială, cea pe care încercăm să o prezicem. Orice coloană poate fi o etichetă (label) în funcție de problema pe care încercăm să o rezolvăm.
În formula următoare, valorile x sunt coloanele, iar f este modelul nostru care prezice eticheta Y.
Y = f(x1, x2, …xn)
Evident, nu vom înțelege foarte multe doar uitându-ne la datele analitice din tabel, dar Jupyter Notebook oferă mai multe tipuri de diagrame (prin librăria XPlot.Plotly) pentru a agrega datele într-o manieră mai utilă.
Să vedem care sunt categoriile de date.
var categories = trainingData.GetColumn<string>("Label");
var categoriesHistogram = Chart.Plot(
new Graph.Histogram { x = categories }
);
display(categoriesHistogram);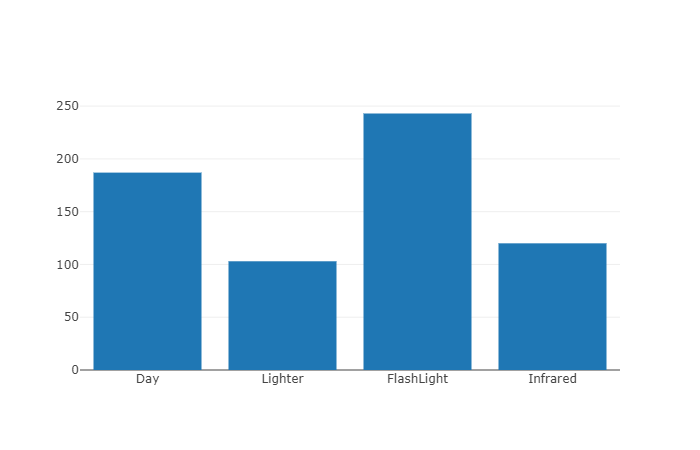
Segmentarea seturilor (Plot Segmentation)
Dacă dorim să avem mai multe informații despre datele noastre, putem folosi plot segmentation.
var featuresTemperatures = features.Select(f => f.Temperature);
var featuresLuminosities = features.Select(f => f.Luminosity);
var featuresInfrareds = features.Select(f => f.Infrared);
var featuresDistances = features.Select(f => f.Distance);
var featuresDiagram = Chart.Plot(new[] {
new Graph.Box { y = featuresTemperatures, name = "Temperature" },
new Graph.Box { y = featuresLuminosities, name = "Luminosity" },
new Graph.Box { y = featuresInfrareds, name = "Infrared" },
new Graph.Box { y = featuresDistances, name = "Distance" }
});
display(featuresDiagram);
Consultând diagrama, putem extrage informații utile precum:
- Valoarea Mediană pentru Distance este mai mare comparativ cu alte coloane
- Valorile min-max values pentru Temperature și Infrared nu sunt distribuite uniform
- Temperature are multe date periferice (outliers)
Putem folosi această informație ulterior pentru a îmbunătăți acuratețea modelului.
Pentru a pregăti datele, să ne amintim că lucrăm cu o mașină și că trebuie să transformăm toate datele categoriale (text) în numere, folosind transformatori categoriali precum OneHotEncoding.
Matricea de corelații (Correlation Matrix)
Când vorbim despre date, apare o altă întrebare: Chiar avem nevoie de toate coloanele (features)? E foarte probabil ca unele să fie mai puțin importante decât altele. Matricea de corelații este un instrument excelent pentru a măsura corelațiile dintre coloane (features) astfel:
- Valorile apropiate de -1 sau 1 indică o relație puternică (proporționalitate).
- Valorile apropiate de 0 indică o relație slabă.
- Valoarea 0 indică absența unei relații.
Următoarea porțiune de cod ar putea să arate încărcată, dar trebuie să pregătim datele pentru matricea de corelații și să le afișăm normalizat, iar pentru acest lucru trebuie să aliniem valorile în perechi și să apelăm funcția Correlation.Pearson.
#r "nuget:MathNet.Numerics, 4.9.0"
using MathNet.Numerics.Statistics;
var featureColumns = new string[] { "Temperature", "Luminosity", "Infrared", "Distance" };
var correlationMatrix = new List<List<double>>();
correlationMatrix.Add(featuresTemperatures.Select(x => (double)x).ToList());
correlationMatrix.Add(featuresLuminosities.Select(x => (double)x).ToList());
correlationMatrix.Add(featuresInfrareds.Select(x => (double)x).ToList());
correlationMatrix.Add(featuresDistances.Select(x => (double)x).ToList());
var length = featureColumns.Length;
var z = new double[length, length];
for (int x = 0; x < length; ++x)
{
for (int y = 0; y < length - 1 - x; ++y)
{
var seriesA = correlationMatrix[x];
var seriesB = correlationMatrix[length - 1 - y];
var value = Correlation.Pearson(seriesA, seriesB);
z[x, y] = value;
z[length - 1 - y, length - 1 - x] = value;
}
z[x, length - 1 - x] = 1;
}Să afișăm matricea de corelații.
var correlationMatrixHeatmap = Chart.Plot(
new Graph.Heatmap
{
x = featureColumns,
y = featureColumns.Reverse(),
z = z,
zmin = -1,
zmax = 1
}
);
display(correlationMatrixHeatmap);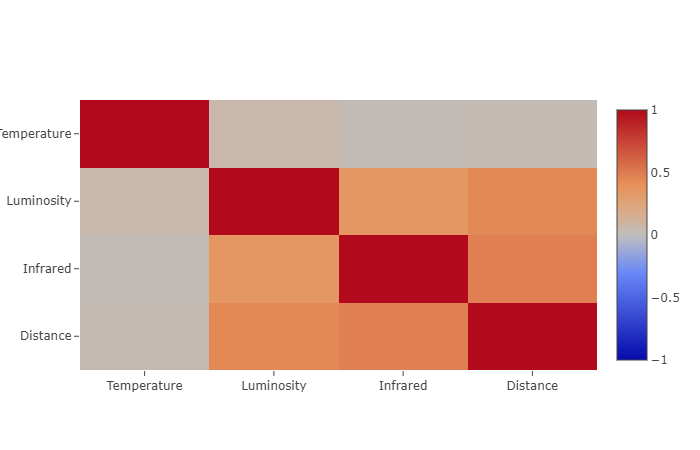
Coloanele (features) corelate puternic nu transmit informații suplimentare (se influențează una pe alta foarte puternic). Prin urmare, o puteți elimina pe cea care are cea mai mare corelație medie absolută (mean absolute correlation) cu alte coloane (features), însă nu e cazul în situația noastră unde avem nevoie de toate.
De exemplu, cele mai corelate coloane (features) sunt Distance și Infrared (0.48), iar Temperature este cea mai puțin corelată coloană (feature) comparativ cu celelalte.
Construiți o linie (pipeline) de preprocesare a datelor
ML.NET se așteaptă să găsească datele de intrare pe coloana Features, iar datele de ieșire pe coloana Label. Dacă aveți astfel de coloane, nu trebuie să le furnizați voi. În caz contrar, trebuie să efectuați niște transformări de date pentru a expune aceste coloane transformatorilor.
Mai mult, dacă trebuie să facem clasificare binară sau multiplă, trebuie să convertim eticheta (label) în numere folosind MapValueToKey.
În cele mai multe dintre cazuri, va trebui să antrenăm mai mult de o coloană (feature) pentru modelul nostru, iar apoi să le concatenăm ca parte a coloanei menționate anterior (numită Features).
var featureColumns = new string[] { "Temperature", "Luminosity", "Infrared", "Distance" };
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.Concatenate("Features", featureColumns));Avem acum o linie de preprocesare a datelor și putem începe pregătirea modelului, în partea doua a acestei serii.
1 thought on “[Romanian] Machine Learning 101 cu Microsoft ML.NET (partea 1/3)”
Comments are closed.